
機械学習とは「データから規則性や判断基準を学習し、それに基づき未知のものを予測、判断する技術」と人工知能に関わる分析技術を指しています。
Treasure Data CDPも、機械学習を用いて予測モデルを生成する機能「Predictive Scoring」や機械学習の分野で最もシェアが高いプログラミング言語のPythonを実行できる「Custom Script」を持っており、特定行動をする可能性のある顧客を予測することができるようになります。
ただし当然ながら、大量のデータがあればすぐに精度の高い予測モデルが作られるわけではありません。そこには、予測モデルを開発するためのプロセスが存在します。どのようなプロセスで開発されるのでしょうか。トレジャーデータのデータマネジメントチームで統計モデルの開発・実装を担当している小野が解説します。
小野 岳洋
トレジャーデータ株式会社
Data Management
2020年にトレジャーデータに参画。データマネジメントチームにて、Treasure Data CDPの導入・構築・運用、統計モデルの開発・実装を担当。得意領域は機械学習を含めた統計モデル開発
予測モデルとは
予測モデルとは、顧客の購買確率予測や集客予測に利用される統計モデルです。購買確率を予測することで営業先の優先順序を決定したり、集客人数や機械の故障率を予測することで社内のリソースを管理したり、解約率を予測することで将来の収益を推測したりします。近年はAIや機械学習の発展や多量のデータを扱うことにより、その精度を大幅に向上させることができています。
予測モデルは、入力側のデータを入れると予測結果が出力される構造になっています。予測には数値予測、確率予測、カテゴリ予測などがあり、例えば以下のような構造になっています。
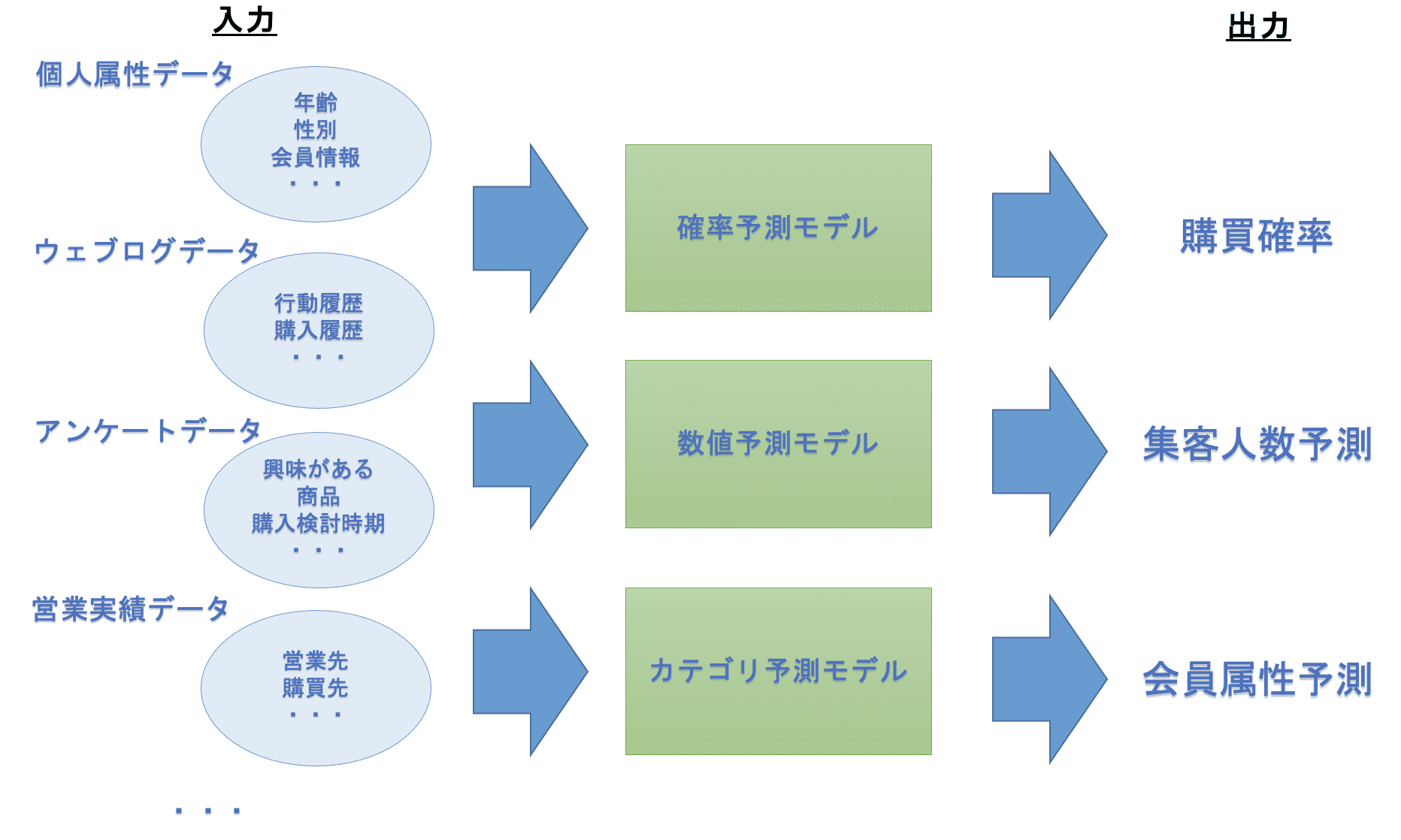
機械学習は予測モデルのアルゴリズムとして使われることが多く、そのモデル開発は開発者の流儀や使用するアルゴリズムなどの違いがあるため、誰もがいつも同じプロセスを踏むわけではありません。下記では、私が踏んでいる手順の大枠を説明します。
予測モデルの開発プロセス
- モデル概要の定義
ビジネスにおけるモデルを開発する意義や機能、アルゴリズムや開発手順を定義します。例えば「営業戦略に利用するため、ロジスティック回帰を利用し購買確率予測モデルを作成する」などです。特に、モデルの対象範囲や責任範囲が定まっていないと、出戻りする場合や議論の収拾がつかなくなる恐れがあります。 - データの準備 ー探索的データ分析(EAD)、データ精査
データを俯瞰し、構造を把握します。また、利用するデータが正しく格納されモデル開発に利用できるかを確認します。定義通りに格納されているか、欠損が多すぎないか、異常値はないか、分布が現場との感覚に沿っているかなどを整理します。 テーブル一覧、ER図、要約統計量、欠損や異常値の割合などを作成します。 - データの作成
- 分析テーブルの作成
2で確認した内容をもとに、データを結合し、使えない項目を削除し分析用のテーブルを作成します。
1で定義した要件を満たすよう目的変数を定義し結合します。 - 変数の加工、取捨選択
説明変数となる項目とその離散化や合成変数を作成し、目的変数への説明力を分析し、カテゴリの数を調整します。
パターンにより使える変数が異なる場合など、モデルを分割する必要があるかも確認します。
- 分析テーブルの作成
- モデル構築
1で定義したひとつ、または複数のアルゴリズムでモデルを構築します。 トレーニング用と検証用にデータを分割し、両方の精度を見ながらアルゴリズムとパラメータを選択します。 - モデル評価
5で構築したモデルが実利用に則しているかを検証します。 主要な変数、安定性、ロバスト性(堅牢性)、特定変数への依存、出力の分布の偏り、実績や新旧モデル出力の差、実利用に沿っているか、モデルを導入した際のコストパフォーマンスなどを確認します。
おわりに
今回は、私が行っている予測モデル開発のプロセスを大枠で解説しました。プロセスの概要を掴んでいただけたら幸いです。

業界に精通した担当者が直接ご説明します
無料相談ルーム
相談無料!オンラインでお気軽にご相談いただけます


.jpg?width=450&height=250&name=C-6%20%CC%B3%E6%8A%95%E7%A8%BF%E7%94%A8%20(1).jpg)



